
Introduction au NoSQL
 NoSQL signifie “Not Only SQL”, littéralement “pas seulement SQL”. Ce terme désigne l’ensemble des bases de données qui s’opposent à la notion relationnelle des SGBDR. La définition, “pas seulement SQL”, apporte un début de réponse à la question “Est ce que le NoSQL va tuer les bases relationnelles?”. En effet, NoSQL ne vient pas remplacer les BD relationnelles mais proposer une alternative ou compléter les fonctionnalités des SGBDR pour donner des solutions plus intéressantes dans certains contextes.
NoSQL signifie “Not Only SQL”, littéralement “pas seulement SQL”. Ce terme désigne l’ensemble des bases de données qui s’opposent à la notion relationnelle des SGBDR. La définition, “pas seulement SQL”, apporte un début de réponse à la question “Est ce que le NoSQL va tuer les bases relationnelles?”. En effet, NoSQL ne vient pas remplacer les BD relationnelles mais proposer une alternative ou compléter les fonctionnalités des SGBDR pour donner des solutions plus intéressantes dans certains contextes.
Le premier besoin fondamental auquel répond NoSQL est la performance. En effet, ces dernières années, les géants du Web comme Google et Amazon ont vu leurs besoins en termes de charge et de volumétrie de données croître de façon exponentielle. Et c’est pour répondre à ces besoins que ses solutions ont vu le jour. Les architectes de ces organisations ont procédé à des compromis sur le caractère ACID des SGBDR. Ces intelligents compromis sur la notion de relationnel ont permis de dégager les SGBDR de leurs freins à la scalabilité horizontale et à l’évolutivité. Par la suite des entreprises comme Facebook, Twitter ou encore LinkedIn ont migré une partie de leurs données sur des bases NoSQL. Cette adoption croissante des bases NoSQL conduit à une multiplication et une amélioration des offres Open Source des moteurs.
Plus de relationnel, mais quelles autres caractéristiques?
Ne plus répondre au modèle relationnel est la caractéristique principale des bases de données NoSQL. Les bases de données NoSQL répondent aussi au théorème du CAP d’Eric Brewer qui est plus adapté aux systèmes distribués. Ce théorème énonce que tout système distribué peut répondre aux contraintes suivantes:
- Cohérence : tous les noeuds du système voient exactement les mêmes données au même moment
- Haute disponibilité (Availability) : en cas de panne, les données restent accessibles
- Tolérance au Partitionnement : le système peut être partitionné
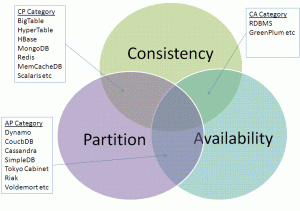
Mais le théorème du CAP précise aussi que seulement deux de ces trois contraintes peuvent être respectées en même temps.
D’autres caractéristiques communes aux différentes bases de données NoSQL peuvent être citées tel que le partitionnement horizontal sur plusieurs noeuds, la réplication des données, les schémas dynamiques ou l’absence de schéma.
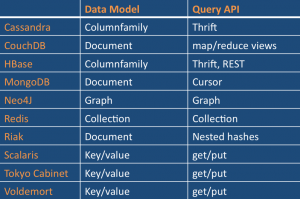
Il existe donc les bases de données NoSQL de type :
Clé / valeur : Ce modèle peut être assimilé à une hashmap distribuée. Les données sont, donc, simplement représentées par un couple clé/valeur. La valeur peut être une simple chaîne de caractères, un objet sérialisé… Cette absence de structure ou de typage ont un impact important sur le requêtage. En effet, toute l’intelligence portée auparavant par les requêtes SQL devra être portée par l’applicatif qui interroge la BD. Néanmoins, la communication avec la BD se résumera aux opérations PUT, GET et DELETE. Les solutions les plus connues sont Redis, Riak et Voldemort créé par LinkedIn.
Orienté colonne : Ce modèle ressemble à première vue à une table dans un SGBDR à la différence qu’avec une BD NoSQL orientée colonne, le nombre de colonnes est dynamique. En effet, dans une table relationnelle, le nombre de colonnes est fixé dés la création du schéma de la table et ce nombre reste le même pour tous les enregistrements dans cette table. Par contre, avec ce modèle, le nombre de colonnes peut varier d’un enregistrement à un autre ce qui évite de retrouver des colonnes ayant des valeurs NULL. Comme solutions, on retrouve principalement HBase (implémentation Open Source du modèle BigTable publié par Google) ainsi que Cassandra (projet Apache qui respecte l’architecture distribuée de Dynamo d’Amazon et le modèle BigTable de Google).
Orienté document : Ce modèle se base sur le paradigme clé valeur. La valeur, dans ce cas, est un document de type JSON ou XML. L’avantage est de pouvoir récupérer, via une seule clé, un ensemble d’informations structurées de manière hiérarchique. La même opération dans le monde relationnel impliquerait plusieurs jointures. Pour ce modèle, les implémentations les plus populaires sont CouchDB d’Apache, RavenDB (destiné aux plateformes .NET/Windows avec la possibilité d’interrogation via LINQ) et MongoDB.
Orienté graphe : Ce modèle de représentation des données se base sur la théorie des graphes. Il s’appuie sur la notion de noeuds, de relations et de propriétés qui leur sont rattachées. Ce modèle facilite la représentation du monde réel, ce qui le rend adapté au traitement des données des réseaux sociaux. La principale solution est Neo4J.
Les deux mouvements “orienté colonne” et “orienté document” découlent bien du système clé valeur et c’est la nature ou la structure de la valeur qui diffère.
Bref, vous l’aurez compris, NoSQL c’est bien, mais c’est pas fait pour remplacer les bases relationnelles. On va plutôt ajouter ce type de base en complément pour optimiser les performances. Donc généralement on trouve très souvent ce type d’archi :
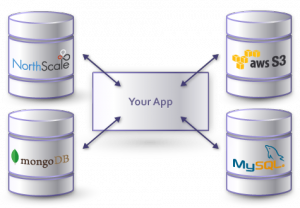
Source : Une bonne partie sur Neoxia
