How we use Neo4J on our social network and workaround performance issues
Neo4J is the most popular graph database in the NoSQL databases family. We’re using it in the Nousmotards project to store all social data through nodes and relationships.
Today I am going to talk about our experience after having using it for 2 years now (take a look at directed graph if you are not really familiar with Graph Database).
1/ Our use case
Nousmotards is a social network for bikers, we aim to provide valuable tools to ride, meet and share nice time with people who like motorcycling.
Neo4j is the way that we manage connections between riders. Connections are how people interact which each others, what they do, how and where.. All actions are represented by relationships (edges) and nodes (vertices).
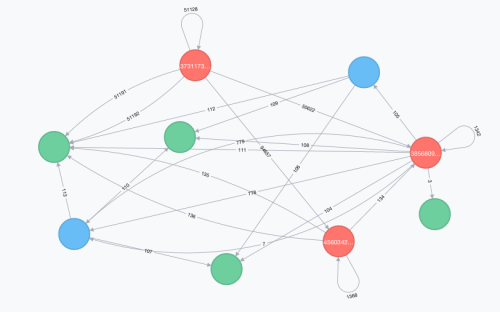
For instance, if you ask someone to be your friend, it’s just a relationship between you and him.

Now imagine that you want to that A ask B as friend, it’s called directed graph.

Each nodes and relationships can have properties. It’s like properties on object instance, but each instance of the same type can have totally different properties if you want. It’s schema free by design.

Our social network is at the moment composed of +100k nodes, +300k relationships and +500k properties. We are accessing Neo4J in server mode by using REST API and more precisely Spring Data Neo4J 3.4.x. Server mode is good to have multiple clients and HA features at the cost of performance (note: If you are looking for intensive graph processing, you should consider using embedded mode or developing your own server extension). This way (using server mode) our micro services can access graph data at anytime.
2/ Fast to implement
At first use, Neo4J was really impressive to find connected data, even if they are really “far away” from each others. Neo Technology has wrote their own query language called “Cypher” and let you express yourself to easily retrieve data. For example getting friends of friends (FOF) is amazingly easy:
MATCH (a: Rider)-[:IS_FRIEND]-(b: Rider)-[:IS_FRIEND]-(c: Rider) WHERE id(a)=123 RETURN c;
And if you want to avoid returning riders who are already friends with A :
MATCH (a: Rider)-[:IS_FRIEND]-(b: Rider)-[:IS_FRIEND]-(c: Rider) WHERE id(a)=123 AND NOT (a: Rider)-[:IS_FRIEND]-(c: Rider) RETURN c;
Definitely easy..
By this way you can start to implement all social features intuitively. This is how we manage friends, likes, who has upload photos, where you live and so much bikers things..
3/ The reality
Let’s talk about reality of using Neo4J and the performance. Nousmotards backend expose its API through RESTful API, which is directly consumed by browser and mobile (Android and iOS) applications. A user will directly consider that your application is bad quality if the time for loading data is too slow. That means your end user app is bad designed or/and that your API to high latency ( > ~2s ) and low throughput.. which means your backend stack is slow to get data, processing them, and send them back to the requester… And this is what happened to us !
The first mistake we made was to think we could be able to fetch data in real time from Neo4J.. That was a really bad idea!
You should simply forget doing this if you are using Neo4J in server mode. Server mode is using REST API and the overhead of opening an http connection > making your request > the server deserializing your request > fetching data > serializing the response > send it back to your application > closing the http connection cost so much that you will never get over it. Note that Spring Data Neo4J is adding an abstraction layer and low performance as well.
How did we figure it out ? By putting a cache layer between our application and Neo4J. This layer intermediate each call to the Neo4J API to retrieve data from Redis at first, and then in Neo4J if they are not available.

This drastically improved the read performance. It’s not only about network overhead, but the way how Neo4J take its time to respond.. They are using locking to ensure data coherence which is a good thing, but this is bad for performance purpose if you’re expecting to read or write data in near real time.
The second problem was to improve write performance.. For almost all databases, what you have to do is to batch your inserts into one statement instead of putting one statement per insert. Neo4J REST API gives you the possibility to do batch insert, but SDN (Spring Data Neo4J) don’t (There is a non official workaround available) ! A user who post a new message, do not want to wait 10s to see his message appearing, this can be a very bad user experience and your app will for sure lose its users..
What we imagine to solve write latency was:
- Use a queue to append write intent into it, then process it in background.
- Respond to the user directly.

This is one part of our solution to improve read and write latency, our average response time is lower to 300ms during all day. Sometimes it can be higher in this configuration, if we access Neo4J to refresh Redis cache during lock on an object that we want to access.
4/ To conclude
Neo4J is definitely a very good product, but lack of community support at this time. It perfectly fit graph usage and it’s very good for analytics but not for concurrent real time access (trough server mode at least).
You can find more info on graph databases and neo4j:
- blog.octo.com/en/graph-databases-an-overview/
- docs.spring.io/spring-data/data-neo4j/docs/3.4.2.RELEASE/reference/html/
To get more informations on nousmotards: blog.nousmotards.com
Join us ! :-)