
Running Cassandra in Kubernetes
![]()
For my own company MySocialApp, I’m managing multiple Cassandra clusters on top of a Kubernetes on premise cluster. For those who never heard of this distributed database, here is the summary from the official website:
The Apache Cassandra database is the right choice when you need scalability and high availability without compromising performance. Linear scalability and proven fault-tolerance on commodity hardware or cloud infrastructure make it the perfect platform for mission-critical data. Cassandra’s support for replicating across multiple datacenters is best-in-class, providing lower latency for your users and the peace of mind of knowing that you can survive regional outages.
What does that mean having a Cassandra cluster in a Kubernetes on premise cluster? Here are the basics:
- Data location: having data means, you should be able to know where they are located (physically, or should be able to access them in a known way). You can’t run a Cassandra instance anywhere if you’re not sure the data will be there and if you care about your data (of course).
- Performance: distributed storage on top of a distributed database is strongly discouraged if you’re searching for the best performances.
- Observability: distributed solutions are generaly more complex to observe. The observability tooling around it must be good enough to easily troubleshot.
- Self management: having a Cassandra self managed solution on Kubernetes is a good idea, however managing all scenario cases on distributed systems is a very long and complex achievement.
That’s why in this blog post, you’ll see how I made a Cassandra helm chart, what are the benefits based on my experience on Cassandra + Kubernetes and finally how it works.
Performances
Cassandra require a local storage to get the best performances. That’s why you should avoid using distributed storage and use a hostPath or localstorage configuration like:
volumes:
- name: cassandra-data
hostPath:
path: /mnt/data/{{ .Release.Namespace }}/cassandraMore than that, Cassandra maanges by itself replication. Let’s say you’ve got a RF (Replication Factor) of 3, your data is available on 3 nodes. If you’re using a distributed storage on top of Cassandra, it certainly also has a x3 RF. Which mean the same data is stored 9 times. That’s a huge waste of space and money in addition of the performances.
Another thing, I’ve added some default Cassandra options, however I recommend to update the Cassandra configuration settings according to your hardware and wishes:
cassandraConfig:
concurrentWrites: 128
concurrentReads: 128
concurrentCompactors: 2
batchSizeWarnThresholdInKb: 64
batchSizeFailThresholdInKb: 640
compactionThroughputMbPerSec: 150
heapNewSize: 256M
hintedHandoffThrottleInKb: 4096
maxHeap: 4G
maxHintsDeliveryThreads: 4
memtableAllocationType: "offheap_objects"
memtableFlushWriter: 4
memtableCleanupThreshold: 0.2
rowCacheSizeInMb: 128
rowCacheSavePeriod: 14400To reduce performance issues as well and reduce cluster failure in case of an issue, I should avoid getting multiple instances on the same physocal host. For that I’m using podAntiAffinity:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- {{ template "kubernetes.name" . }}
topologyKey: kubernetes.io/hostnameYou can also tune the JVM memory allocation and parameters to optimize memory usage in a container.
Statefulset & self management
Statefulset
On this Cassandra helm chart, I decided to use Statefulset because:
- It understands the complexity of most of the stateful applications and have a the corresponding behavior
- The given naming convention is simple to follow:
cassandra-X - Coupled with a
PodDisruptionBudget, it brings a safetier solution - With postStart and preStop hooks, I’m able to define the tasks I want to address to the Cassandra cluster
Upgrade stategy
Regarding the rollout and rolling upgrade/restart strategy, it’s really simple with this kind of rules on a Statefulset, I’m sure the procedure won’t go too fast:
updateStrategy:
type: "RollingUpdate"Pod disruption budget
Using the PodDisruptionBudget, I’m also sure I won’t have more than 1 (the default) planned node down in my cluster. With a RF of 3, I know I can loose a node during a rolling restart:
maxUnavailable: {{ .Values.cassandraMaxUnavailableNodes }}
selector:
matchLabels:
app: {{ template "kubernetes.name" . }}Run override
I also added an override script to replace run.sh for several reasons:
- Prerequisites: I wanted to set some global variables first requiring shell and pipes stuffs.
- Flexibility: it makes possible to add specific command before the instance start. This could be very be useful if you need to run at a given time some commands, but can’t rolling restart the whole cluster. This already saved my life twice.
#!/bin/bash
source /usr/local/apache-cassandra/scripts/envVars.sh
/usr/local/apache-cassandra/scripts/jvm_options.sh
/run.shPost start hook
In the pre start hook:
- I’m ensuring the service is up and running
- I’m registering the cluster to Cassandra reaper if not already done (will talk later about Cassandra Reaper)
#!/bin/bash
source /usr/local/apache-cassandra/scripts/envVars.sh
until /ready-probe.sh ; do
echo "Waiting node to be ready"
sleep 1
done
{{- if .Values.cassandraReaper.enabled }}
# Wait until replicas is 3 to ready Cassandra Reaper database
if [ "$(hostname)" == 'cassandra-2' ] ; then
cqlsh -e "CREATE KEYSPACE IF NOT EXISTS reaper_db WITH replication = {'class': 'NetworkTopologyStrategy', '{{ .Values.cassandraDC }}': 3};" > /var/log/reaperdb.log
fi
{{- end }}
{{- if .Values.cassandraReaperRegister.enableReaperRegister }}
# Register cluster into Cassandra Reaper
# Do not target current instance to avoid unready instance status (and registration failure)
if [ "$(hostname)" == 'cassandra-0' ] ; then
seedHost=$(hostname -A | sed 's/^cassandra-0/cassandra-1/')
else
seedHost=$(hostname -A | sed -r 's/^cassandra-\w+(\..+)/cassandra-0\1/')
fi
# Check if cluster needs to be registred or simply updated
counter=0
if [ $(curl -s "http://{{ .Values.cassandraReaperRegister.reaperServerServiceName }}/cluster" | grep -c $CASSANDRA_CLUSTER_NAME) == 0 ] ; then
while [ $(curl -s -I -X POST "http://{{ .Values.cassandraReaperRegister.reaperServerServiceName }}/cluster?seedHost=$seedHost" | grep -c "^HTTP/1.1 201 Created") != 1 ] ; do
if [ $counter == 5 ] ; then
break
fi
counter=$((counter+1))
sleep 5
done
else
while [ $(curl -s -I -X PUT "http://{{ .Values.cassandraReaperRegister.reaperServerServiceName }}/cluster/${CASSANDRA_CLUSTER_NAME}?seedHost=$seedHost" | egrep -c "^HTTP/1.1 (200|304)") != 1 ] ; do
if [ $counter == 5 ] ; then
break
fi
counter=$((counter+1))
sleep 5
done
fi
{{- end }}
exit 0Pre stop hook
In the pre stop hook:
- I’m ensure the correct health of the cluster before requesting node leave. This to avoid a total blackout
- I’m ensuring the node stops properly
#!/bin/sh
run_nodetool() {
echo "Running: nodetool $1"
/usr/local/apache-cassandra/bin/nodetool $1
sleep 5
}
while [ $(/usr/local/apache-cassandra/bin/nodetool status | awk "/$CASSANDRA_RACK/{ print \$1,\$2 }" | grep -v $POD_IP | awk '{ print $1 }' | grep -v UN) -eq 0 ] ; do
echo "Waiting all nodes to recover a correct status before draining this node"
sleep 5
pidof java || exit 1
done
run_nodetool disablethrift
run_nodetool disablebinary
run_nodetool disablegossip
run_nodetool flush
run_nodetool drain
sleep 10
run_nodetool stop
run_nodetool stopdaemon
exit 0Observability
Observing a Cassandra cluster may not be an easy task. There are plenty of metrics per nodes which can confuse the beginners. That’s why providing an exporter with a pre-made Grafana dashboard is a good solution for everyone.
Cassandra exporter
To make it simple, I’m using the Prometheus format (as it becomes the standard now) and I’m using Cassandra Exporter (made by my NoSQL team at Criteo).
On each nodes it will deploy an exporter (an additional container in the Cassandra pod):
# Cassandra Exporter
cassandraExporter:
enableExporter: false
replicaCount: 1
imageVersion: 1.0.2
nodeSelector:
node-role.kubernetes.io/node: "true"
resources:
limits:
cpu: 300m
memory: 500Mi
requests:
cpu: 300m
memory: 500Mi
config:
host: 127.0.0.1:7199
listenPort: 8080
jvmOpts: ""
# Prometheus scraping
cassandraPrometheusScrap:
enableScrap: falseIf you’re using Prometheus Operator, you can enable automatic scraping here (mean that Prometheus server will automatically retrieve information from exporter).
Grafana
A Cassandra dashboard compatible with Kubernetes is also available here.
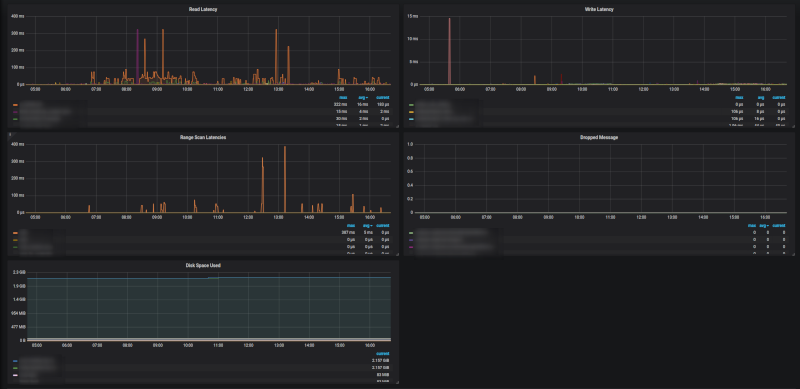
You only have to import it in your Grafana interface.
Alerting
Once again, if you’re using Prometheus Operator, you can enable basic alerting rules with Alert Manager:
cassandraAlertmanager:
enableAlerts: true
alertLabels:
sloInterrupt:
serviceLevel: objective
severity: interrupt
team: infra
type: functional
sloPage:
serviceLevel: objective
severity: page
team: infra
type: functionalMaintenance and operations
On Cassandra, there are 2 others important actions:
- Backups: as usual, it’s always preferable to get backups (just in case)
- Repair: repair tables to ensure consistency
Backups / Restore
Backuping Cassandra is not so trivial. That’s why I’ve made some scripts included in the helm chart ready to plan backups and help on restore.
The backups scripts are made to store on AWS S3. A cronjob exist for it, you simple have to set the “cassandraBackup” parameters.
Enbale backups
To enable backups, you simply have to update this section with your options. A Cron job will be created to perform backups of all nodes at the same time (for consistency purpose):
cassandraBackup:
enableBackups: true
backupSchedule: "0 3 * * *"
backupImageVersion: v0.1
awsAccessKeyId: "xxx"
awsSecretAccessKey: "yyy"
awsPassphrase: "zzz"
awsBucket: "bucket_name"
#duplicityOptions: "--archive-dir /var/lib/cassandra/.duplicity --allow-source-mismatch --s3-european-buckets --s3-use-new-style --copy-links --num-retries 3 --s3-use-multiprocessing --s3-multipart-chunk-size 100 --volsize 1024 full . s3://s3.amazonaws.com/cassandra-backups/$CLUSTER_DOMAIN/$CASSANDRA_CLUSTER_NAME/$(hostname)"
awsDestinationPath: "s3://s3-eu-west-1.amazonaws.com/${AWS_BUCKET}/$CLUSTER_DOMAIN/$CASSANDRA_CLUSTER_NAME/$(hostname)"
restoreFolder: "/var/lib/cassandra/restore"List
To list backups for a statefulset instance, connect to an instance like in this example and call the script:
kubectl exec -it cassandra-0 bash
/usr/local/apache-cassandra/scripts/snapshot2s3.sh list <AWS_ACCESS_KEY_ID> <AWS_SECRET_ACCESS_KEY> <AWS_PASSPHRASE> <AWS_BUCKET>Replace all AWS information with the corresponding ones.
Restore
To restore backups, configure properly the “restoreFolder” var and run this command:
kubectl exec -it cassandra-0 bash
/usr/local/apache-cassandra/scripts/snapshot2s3.sh restore <AWS_ACCESS_KEY_ID> <AWS_SECRET_ACCESS_KEY> <AWS_PASSPHRASE> <AWS_BUCKET> <RESTORE_TIME>RESTORE_TIME should be used as described in the Duplicity manual Time Format section. For example (3D to restore the the last 3 days backup)
You can then use the script cassandra-restore.sh to restore a desired keyspace with all or one table:
/usr/local/apache-cassandra/scripts/cassandra-restore.sh /var/lib/cassandra/restore/var/lib/cassandra/data [keyspace]Try to use help if you need more info about it.
Repair tables
Repairing tables may be painfull sometimes. Hopefully Cassandra Reaper helps to avoid managing it manually.
You can deploy a server instance (require a Cassandra backend):
cassandraReaper:
enableReaper: true
replicaCount: 1
imageVersion: 1.1.0
nodeSelector:
node-role.kubernetes.io/node: "true"
contactPoints: cassandra-0.cassandra
jmxAuth:
username: reaperUser
password: reaperPass
# clusterName:
# keyspace: reaper_db
envVariables:
JAVA_OPTS: "-XX:+UnlockExperimentalVMOptions -XX:+UseCGroupMemoryLimitForHeap -XX:MaxRAMFraction=2 -XX:+AlwaysPreTouch"
REAPER_CASS_KEYSPACE: reaper_db
REAPER_REPAIR_PARALELLISM: DATACENTER_AWARE
REAPER_REPAIR_INTENSITY: 0.5
REAPER_AUTO_SCHEDULING_ENABLED: true
REAPER_SCHEDULE_DAYS_BETWEEN: 2
REAPER_REPAIR_RUN_THREADS: 16
REAPER_HANGING_REPAIR_TIMEOUT_MINS: 30
REAPER_REPAIR_MANAGER_SCHEDULING_INTERVAL_SECONDS: 10
REAPER_SEGMENT_COUNT: 200
REAPER_LOGGING_ROOT_LEVEL: INFO
REAPER_SERVER_ADMIN_PORT: 8081
REAPER_SERVER_APP_PORT: 8080
REAPER_METRICS_ENABLED: true
resources:
limits:
cpu: 500m
memory: 500Mi
requests:
cpu: 500m
memory: 500MiAnd then you simply have enable client registration to get all your nodes and cluster automatically added into Cassandra Reaper:
cassandraReaperRegister:
enableReaperRegister: true
reaperServerServiceName: cassandra-reaper.svcFinally you’ll find the reaper interface available:
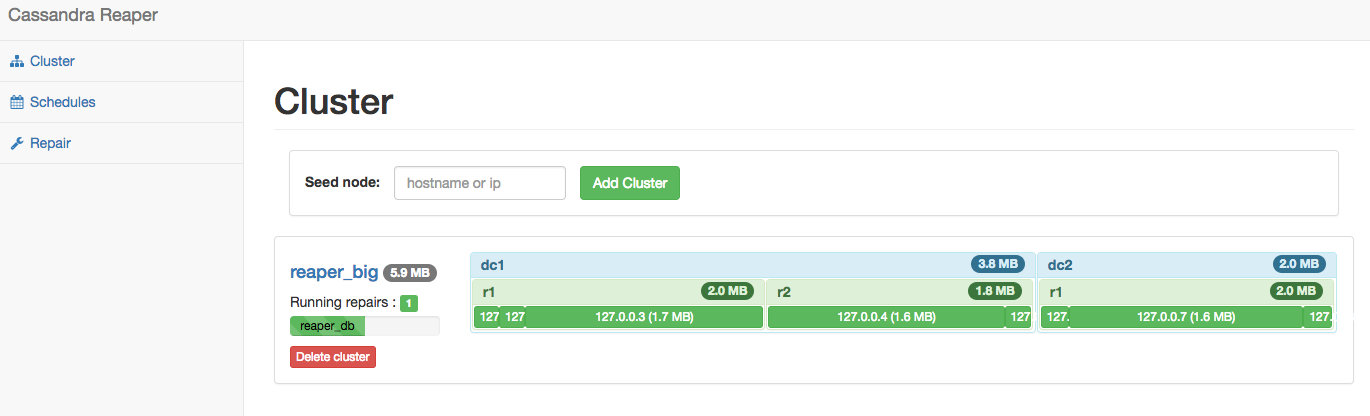
Conclusion
This Cassandra helm chart is helping me day to day. It gives a lot of autonomy to my cluster, gives me the possibility to switch to fallback to a manual way to manage specific Cassandra cases, gives enough automation to avoid spending too many time on managing my Cassandra clusters. I’m pretty well satisfied of this solution.
Some of you may think an Operator would be preferable, that’s true. However in nowdays, there is no stable enough Operator managing Cassandra. Writing one takes some time and I unfortunately do not get this time today (but be happy to participate if a serious initiative is driven) and getting one ready to handle every situations will require a ton of tests and time.
So feel free to participate and I hope you’ll enjoy it :)
