
Merging from one branch to another branch is something common with Git. I had to do it several times and recently I had to make a big one. I’ve just never took the time to look at what exist to make faster merge and how to use it.
After some researches, I found git mergetool which will use VIM (by default on my laptop) to have a better view on what I have to do, to merge my files.
You may upgrade your Mac OS X version to Yosemite (10.10) and saw you dual boot with Linux not working anymore :-(.
That’s because Apple made changes and Refind is not yet ready for it. So here is the solution to get your dual boot half back. It won’t fully work as expected, but you’ll be able to boot to Linux with Refind and Mac OS X with the alt key.
A colleague talked to me about this tool this week and I felt in love. It helps to easily navigate into your git repository. You can have a look on last log and directly in the same interface the diff of the current commit. I’ve attached one screenshot to let you see how cool it is.
The are also a lot of other features but just for browsing purpose. You can’t update or make changes.
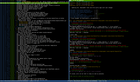
Fig is a fast, isolated development environments using Docker. For some features, it can be compared to Vagrant where the Dockerfike is not enough powerful to build multiple instances.
For example, let’s say you want to test a new product version of a software like MediaWiki and you want to build the complete stack. So you may need to have several tools categories (depending of the usage):
Web: Nginx, PHP-FPM, Varnish App Cahing: Redis Search: ElasticSearch In Vagrant you can natively build 3 VM and interconnect them without the need of additional tool.
I recently discover Aptly which permit to manage local Debian repositories. I waited this kind of tools during several years and now I’m really happy.
It is able to manage several repositories, making snapshots, merging snapshots, diff between 2 snapshots, filtering packages to avoid downloading unwanted ones….
This is perfect when you want to test before upgrading a critical infrastructure.
The first thing you generally want to do when you have any new Storage system like SSD, Disk arrays or a Cluster Ceph, is benching. You will want to know how can read and write throughput. FIO is able to do that for you, here is an example:
[global] ioengine=libaio invalidate=1 ramp_time=5 direct=1 size=5G runtime=300 time_based directory=/home [seq-read] rw=read bs=64K stonewall [rand-read] rw=randread bs=4K stonewall [seq-write] rw=write bs=64K stonewall [rand-write] rw=randwrite bs=4K stonewall You then will have a good output of everything you need to know.

I recently been faced on a classical problem on InnoDB which is the fragmentation, but on Galera. InnoDB engine doesn’t defragment on the fly and requires optimize maintenance sometimes to free disk space. But on Galera, which is a fault tolerance and high availability solution, it’s a problem having tables locked by an optimize procedure. Until Galera doesn’t support TokuDB and only fully support InnoDB, we had (with a colleague (Kevin aka Vinek)) to find a solution.
